We are shipping Spidra Tools, a collection of eight free utilities for developers who work with web data. You do not need an account or a credit card to use any of them.
The tools
Website to Markdown — Turn any URL into clean, LLM-ready Markdown. Unlike most converters, this loads the page in a real browser so JavaScript-heavy sites render before conversion. You can strip navigation, footers, ads, and cookie banners to get just the content.
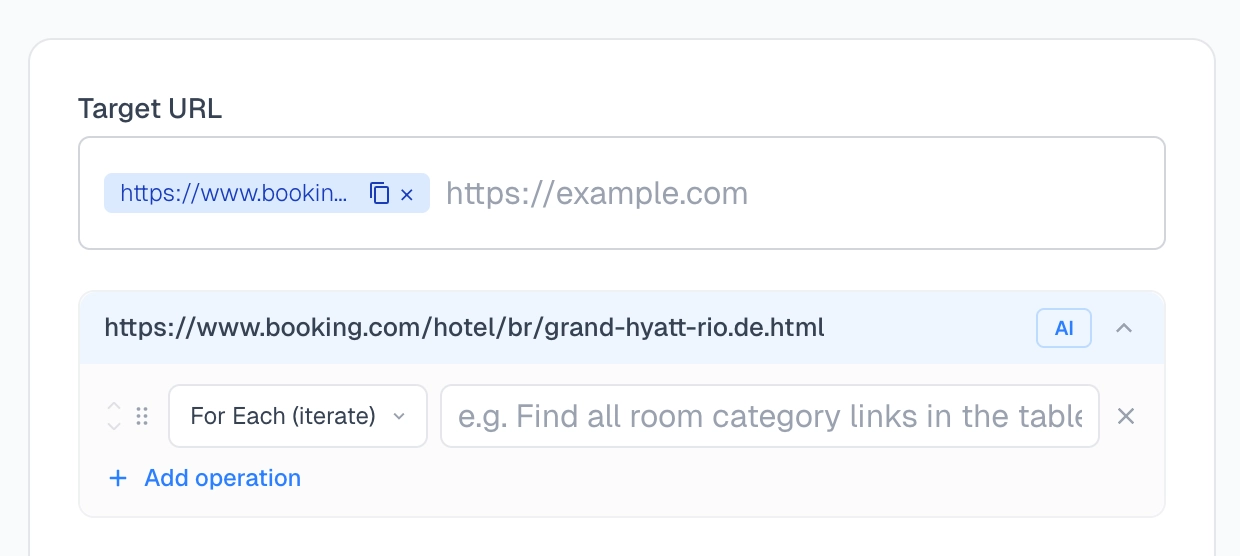
Website to JSON — Describe what you want to extract in plain text and get back structured JSON. The same AI extraction engine that powers the Spidra API, available for free in your browser.
Website Screenshot — Full-page or viewport screenshots of any website. Real browser rendering, downloads as PNG.
AI Question Generator — Paste a URL and generate a set of questions from the page content. You control the number of questions and the format.
JSON Schema Generator — Paste a JSON sample or use the visual builder to generate a valid JSON Schema. Built for use with the Spidra API's structured output feature.
Prettify JSON — Format, validate, and minify JSON. Choose two spaces, four spaces, or tabs. Validates as you paste.
JSON to CSV — Convert any JSON array or object to a CSV file. Pick your delimiter, toggle headers, download instantly.
Markdown to HTML — Live Markdown to HTML conversion with a preview that updates as you type. Full GitHub Flavored Markdown support.
Text Diff Checker — Compare two versions of any text side by side. Additions in green, deletions in red. Runs entirely in your browser — nothing is sent to a server.
What makes the scraping tools different
Website to Markdown, Website to JSON, and Website Screenshot run on the same infrastructure as the Spidra API. Every request loads the page in a real headless browser. JavaScript executes fully, CAPTCHAs get handled, and framework-rendered content populates before anything is extracted. Not a thin HTTP wrapper — actual browser-based rendering, free with no sign-up.
If you need any of this at scale — converting hundreds of pages, extracting structured data from a URL list, crawling a full domain — the Spidra API handles that. Free tier with 300 credits, no card required.